As a long-time fan of GPT-4, I didn’t think any open source coding AI could match its prowess at generating code. But Meta’s new Code Llama model has proven me wrong. Built on Meta’s LLama-2 foundation model and trained on 500 billion tokens of code, it’s optimized specifically for programming – and ready to take on my beloved GPT-4!
According to Meta’s benchmarks, CodeLlama achieved over 67% accuracy on human evaluation tests, surpassing GPT-4’s score of 67%. But how does it compare in real world coding challenges?
Testing Code Generation
I tested Code Llama and GPT-4 on a variety of Python coding prompts, from very easy to intermediate functions and some expert challenges from coding challenge website https://edabit.com/challenges
To test Code Llama 2, I use https://poe.com/code llama 34b parameter model while GPT-4 is tested on my personal ChatGPT Plus code interpreter.
Let’s put code Llama and GPT 4 into side by side test.
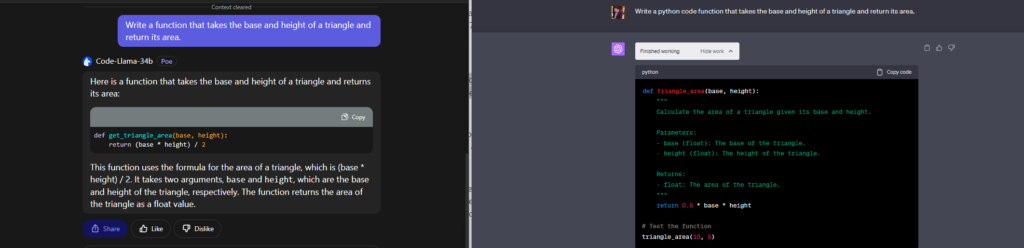
Challenge Task: Write a function that takes the base and height of a triangle and return its area.
Code Snippet For Easy Challange By Both Model
Both models successfully generated the code. However, I liked the fact that GPT4 have explained the code with comments which itself is a coding best practise.
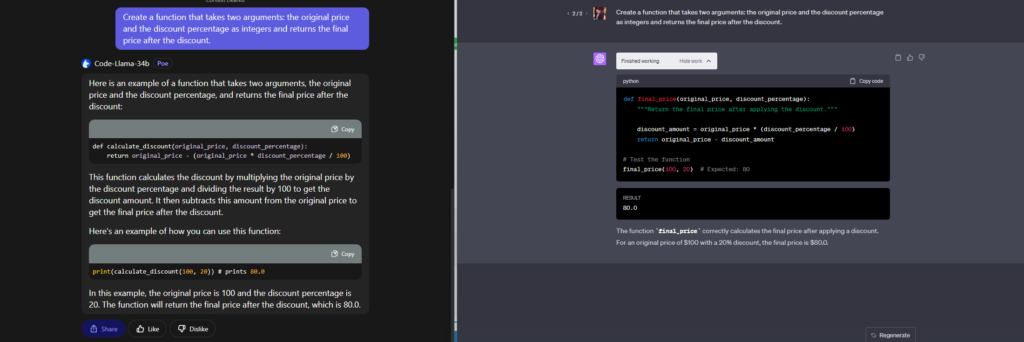
Challenge - Easy - Find the Discount
Challenge Task: Create a function that takes two arguments: the original price and the discount percentage as integers and returns the final price after the discount.
Both Model Completes the Challange with ease
Again both the models generated the code successfully. No sweat.
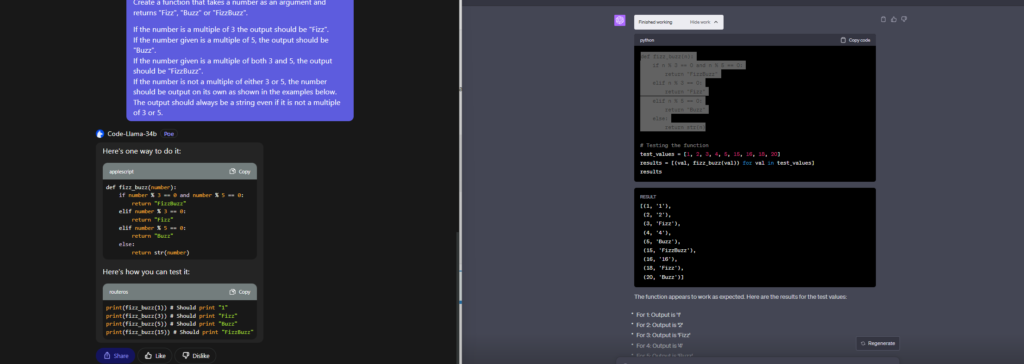
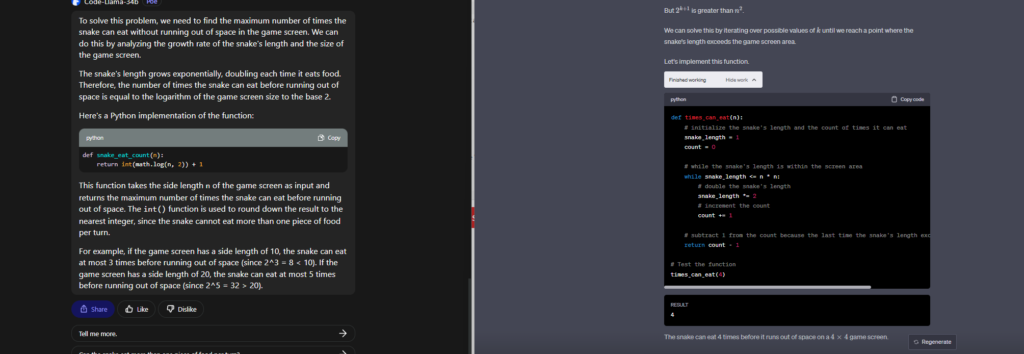
This challenge is based on the classic videogame “Snake”.
Assume the game screen is an n * n square, and the snake starts the game with length 1 (i.e. just the head) positioned on the top left corner. In this version of the game, the length of the snake doubles each time it eats food (e.g. if the length is 4, after eating it becomes 8).
Create a function that takes the side n of the game screen and returns the number of times the snake can eat before it runs out of space in the game screen.
GPT4 Succeeds, Code Llama almost there.
GPT4 clears this hurdle without any hiccups. Although Code Llama logic was close but it couldn’t print the correct code. So GPT4 is now ahead in the race.
We still have very hard and expert mode to try on. Let’s see who wins the race.
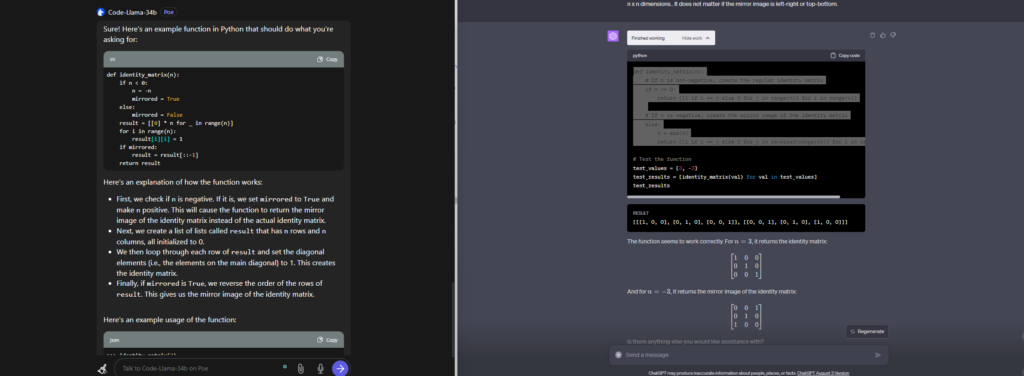
Challenge - Very Hard - Identity Matrix
Challenge Task:
An identity matrix is defined as a square matrix with 1s running from the top left of the square to the bottom right. The rest are 0s. The identity matrix has applications ranging from machine learning to the general theory of relativity.
Create a function that takes an integer n and returns the identity matrix of n x n dimensions. For this challenge, if the integer is negative, return the mirror image of the identity matrix of n x n dimensions.. It does not matter if the mirror image is left-right or top-bottom.
Both GPT4 and Code LLama were very close
Both were very close and passed almost all the unit tests except one. So, the race is still on and GPT4 is just one step ahead.
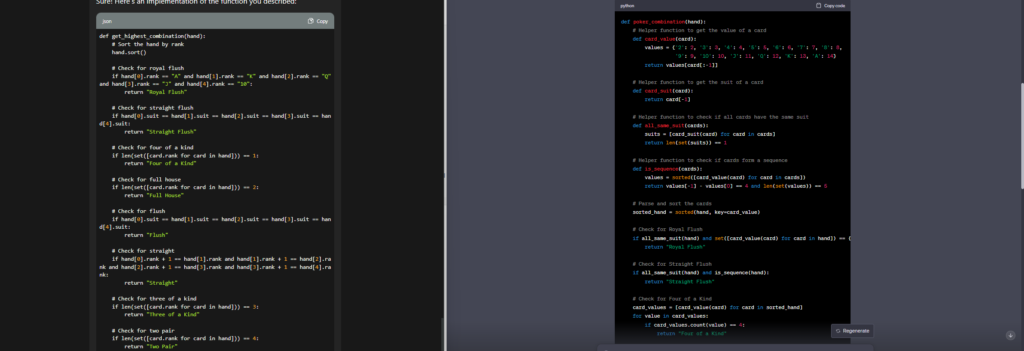
In this challenge, you have to establish which kind of Poker combination is present in a deck of five cards. Every card is a string containing the card value (with the upper-case initial for face-cards) and the lower-case initial for suits, as in the examples below:
"Ah" ➞ Ace of hearts
"Ks" ➞ King of spades
"3d" ➞ Three of diamonds
"Qc" ➞ Queen of clubs
There are 10 different combinations. Here’s the list, in decreasing order of importance:
Name
Description
Royal Flush
A, K, Q, J, 10, all with the same suit.
Straight Flush
Five cards in sequence, all with the same suit.
Four of a Kind
Four cards of the same rank.
Full House
Three of a Kind with a Pair.
Flush
Any five cards of the same suit, not in sequence.
Straight
Five cards in a sequence, but not of the same suit.
Three of a Kind
Three cards of the same rank.
Two Pair
Two different Pair.
Pair
Two cards of the same rank.
High Card
No other valid combination.
Given a list hand containing five strings being the cards, implement a function that returns a string with the name of the highest combination obtained, accordingly to the table above.
GPT4 was correct. Code Llama again was close
GPT4 wins the race. Code llama couldn’t get the expert code right. However, it has left me nothing less than being impressed.
My Final Verdict
Meta’s Code Llama proved it can compete with the mighty GPT-4 for coding tasks! As someone who thought GPT-4 would dominate for years to come, I’m happy to be proven wrong.
This opens up a lot of possibilities for me as I’m planning to create my own Coding Assistant who can create/improve code for me . As Code Llama matures ,it’ll allow me to have my personal AI Employee working 24*7 with a fraction of the cost to do same with GPT4 APIs.
Code Llama is an exciting open source coding AI and I can’t wait to see how it progresses from here!